Inside implementing SuperScraper with Crawlee

SuperScraper is an open-source Actor that combines features from various web scraping services, including ScrapingBee, ScrapingAnt, and ScraperAPI.
A key capability is its standby mode, which runs the Actor as a persistent API server. This removes the usual start-up times - a common pain point in many systems - and lets users make direct API calls to interact with the system immediately.
This blog explains how SuperScraper works, highlights its implementation details, and provides code snippets to demonstrate its core functionality.

What is SuperScraper?
SuperScraper transforms a traditional scraper into an API server. Instead of running with static inputs and waiting for completion, it starts only once, stays active, and listens for incoming requests.
How to enable standby mode
To activate standby mode, you must configure the settings so it listens for incoming requests.
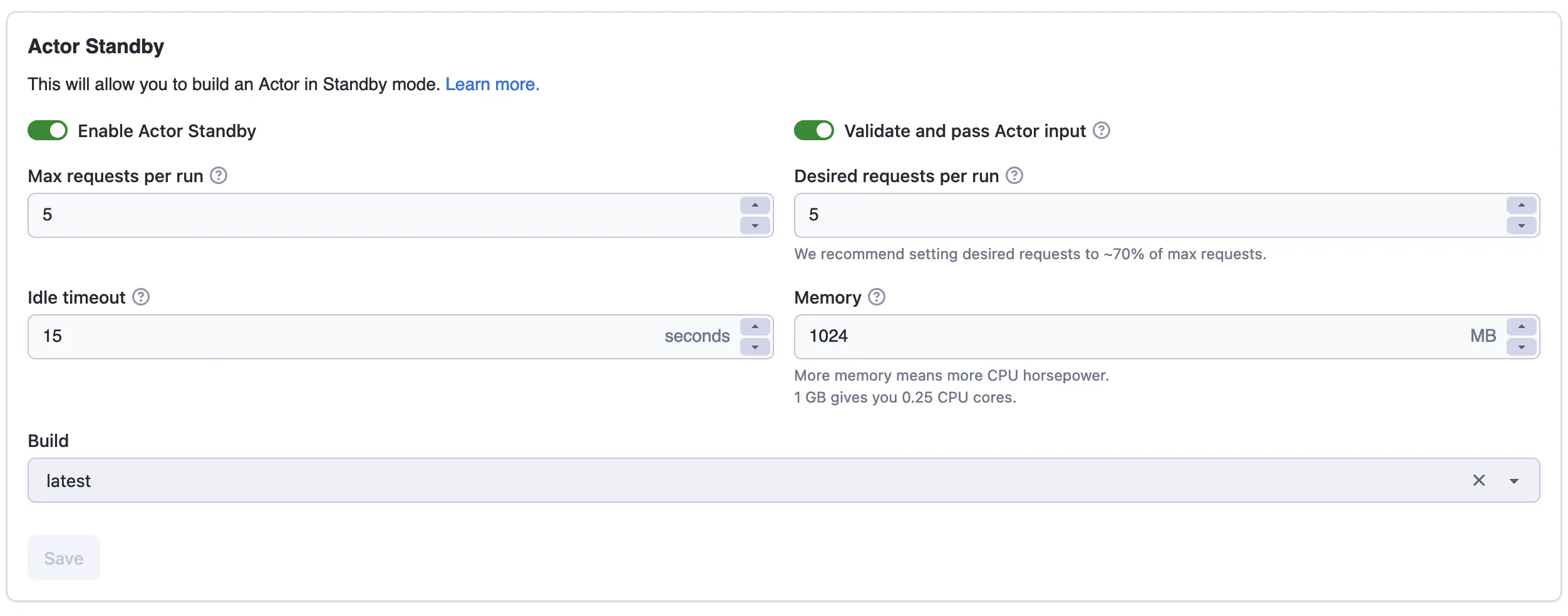
Server setup
The project uses Node.js http module to create a server that listens on the desired port. After the server starts, a check ensures users are interacting with it correctly by sending requests instead of running it traditionally. This keeps SuperScraper operating as a persistent server.
Handling multiple crawlers
SuperScraper processes user requests using multiple instances of Crawlee’s PlaywrightCrawler. Since each PlaywrightCrawler instance can only handle one proxy configuration, a separate crawler is created for each unique proxy setting.
For example, if the user sends one request for “normal” proxies and one request with residential US proxies, a separate crawler needs to be created for each proxy configuration. Hence, to solve this, we store the crawlers in a key-value map, where the key is a stringified proxy configuration.
const crawlers = new Map<string, PlaywrightCrawler>();
Here’s a part of the code that gets executed when a new request from the user arrives; if the crawler for this proxy configuration exists in the map, it will be used. Otherwise, a new crawler gets created. Then, we add the request to the crawler’s queue so it can be processed.
const key = JSON.stringify(crawlerOptions);
const crawler = crawlers.has(key) ? crawlers.get(key)! : await createAndStartCrawler(crawlerOptions);
await crawler.addRequests([request]);
The function below initializes new crawlers with predefined settings and behaviors. Each crawler utilizes its own in-memory queue created with the MemoryStorage client. This approach is used for two key reasons:
- Performance: In-memory queues are faster, and there's no need to persist them when SuperScraper migrates.
- Isolation: Using a separate queue prevents interference with the shared default queue of the SuperScraper Actor, avoiding potential bugs when multiple crawlers use it simultaneously.
export const createAndStartCrawler = async (crawlerOptions: CrawlerOptions = DEFAULT_CRAWLER_OPTIONS) => {
const client = new MemoryStorage({ persistStorage: false });
const queue = await RequestQueue.open(undefined, { storageClient: client });
const proxyConfig = await Actor.createProxyConfiguration(crawlerOptions.proxyConfigurationOptions);
const crawler = new PlaywrightCrawler({
keepAlive: true,
proxyConfiguration: proxyConfig,
maxRequestRetries: 4,
requestQueue: queue,
});
};
At the end of the function, we start the crawler and log a message if it terminates for any reason. Next, we add the newly created crawler to the key-value map containing all crawlers, and finally, we return the crawler.
crawler.run().then(
() => log.warning(`Crawler ended`, crawlerOptions),
() => { }
);
crawlers.set(JSON.stringify(crawlerOptions), crawler);
log.info('Crawler ready 🚀', crawlerOptions);
return crawler;
Mapping standby HTTP requests to Crawlee requests
When creating the server, it accepts a request listener function that takes two arguments: the user’s request and a response object. The response object is used to send scraped data back to the user. These response objects are stored in a key-value map to so they can be accessed later in the code. The key is a randomly generated string shared between the request and its corresponding response object, it is used as request.uniqueKey.
const responses = new Map<string, ServerResponse>();
Saving response objects
The following function stores a response object in the key-value map:
export function addResponse(responseId: string, response: ServerResponse) {
responses.set(responseId, response);
}
Updating crawler logic to store responses
Here’s the updated logic for fetching/creating the corresponding crawler for a given proxy configuration, with a call to store the response object:
const key = JSON.stringify(crawlerOptions);
const crawler = crawlers.has(key) ? crawlers.get(key)! : await createAndStartCrawler(crawlerOptions);
addResponse(request.uniqueKey!, res);
await crawler.requestQueue!.addRequest(request);
Sending scraped data back
Once a crawler finishes processing a request, it retrieves the corresponding response object using the key and sends the scraped data back to the user:
export const sendSuccResponseById = (responseId: string, result: unknown, contentType: string) => {
const res = responses.get(responseId);
if (!res) {
log.info(`Response for request ${responseId} not found`);
return;
}
res.writeHead(200, { 'Content-Type': contentType });
res.end(result);
responses.delete(responseId);
};
Error handling
There is similar logic to send a response back if an error occurs during scraping:
export const sendErrorResponseById = (responseId: string, result: string, statusCode: number = 500) => {
const res = responses.get(responseId);
if (!res) {
log.info(`Response for request ${responseId} not found`);
return;
}
res.writeHead(statusCode, { 'Content-Type': 'application/json' });
res.end(result);
responses.delete(responseId);
};
Adding timeouts during migrations
During migration, SuperScraper adds timeouts to pending responses to handle termination cleanly.
export const addTimeoutToAllResponses = (timeoutInSeconds: number = 60) => {
const migrationErrorMessage = {
errorMessage: 'Actor had to migrate to another server. Please, retry your request.',
};
const responseKeys = Object.keys(responses);
for (const key of responseKeys) {
setTimeout(() => {
sendErrorResponseById(key, JSON.stringify(migrationErrorMessage));
}, timeoutInSeconds * 1000);
}
};
Managing migrations
SuperScraper handles migrations by timing out active responses to prevent lingering requests during server transitions.
Actor.on('migrating', ()=>{
addTimeoutToAllResponses(60);
});
Users receive clear feedback during server migrations, maintaining stable operation.
Build your own
This guide showed how to build and manage a standby web scraper using Apify’s platform and Crawlee. The implementation handles multiple proxy configurations through PlaywrightCrawler instances while managing request-response cycles efficiently to support diverse scraping needs.
Standby mode transforms SuperScraper into a persistent API server, eliminating start-up delays. The migration handling system keeps operations stable during server transitions. You can build on this foundation to create web scraping tools tailored to your requirements.
To get started, explore the project on GitHub or learn more about Crawlee to build your own scalable web scraping tools.