How to scrape Google Maps data using Python

Millions of people use Google Maps daily, leaving behind a goldmine of data just waiting to be analyzed. In this guide, I'll show you how to build a reliable scraper using Crawlee and Python to extract locations, ratings, and reviews from Google Maps, all while handling its dynamic content challenges.
One of our community members wrote this blog as a contribution to the Crawlee Blog. If you would like to contribute blogs like these to Crawlee Blog, please reach out to us on our discord channel.
What data will we extract from Google Maps?
We’ll collect information about hotels in a specific city. You can also customize your search to meet your requirements. For example, you might search for "hotels near me", "5-star hotels in Bombay", or other similar queries.
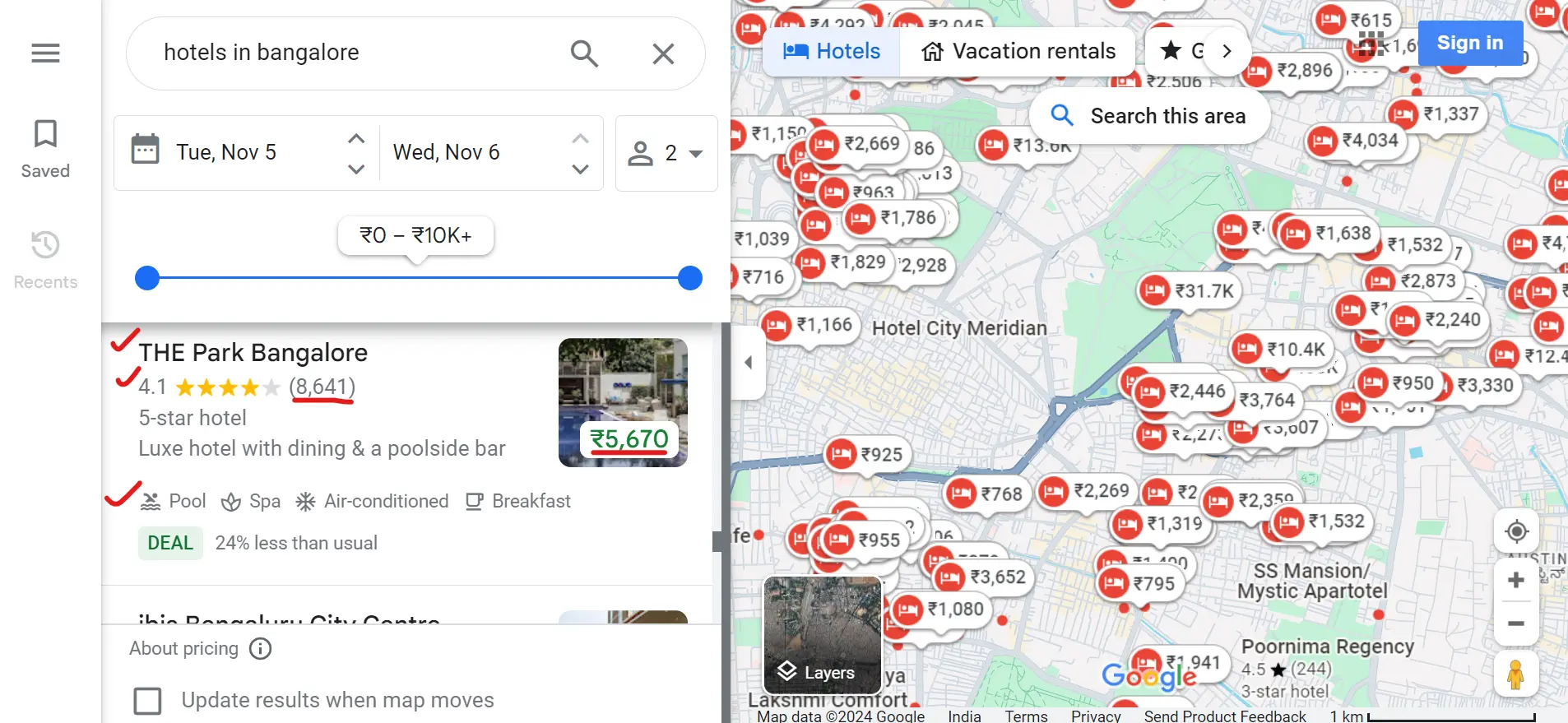
We’ll extract important data, including the hotel name, rating, review count, price, a link to the hotel page on Google Maps, and all available amenities. Here’s an example of what the extracted data will look like:
{
"name": "Vividus Hotels, Bangalore",
"rating": "4.3",
"reviews": "633",
"price": "₹3,667",
"amenities": [
"Pool available",
"Free breakfast available",
"Free Wi-Fi available",
"Free parking available"
],
"link": "https://www.google.com/maps/place/Vividus+Hotels+,+Bangalore/..."
}
Building a Google Maps scraper
Let's build a Google Maps scraper step-by-step.
Crawlee requires Python 3.9 or later.
1. Setting up your environment
First, let's set up everything you’ll need to run the scraper. Open your terminal and run these commands:
# Create and activate a virtual environment
python -m venv google-maps-scraper
# Windows:
.\google-maps-scraper\Scripts\activate
# Mac/Linux:
source google-maps-scraper/bin/activate
# We plan to use Playwright with Crawlee, so we need to install both:
pip install crawlee "crawlee[playwright]"
playwright install
If you're new to Crawlee, check out its easy-to-follow documentation. It’s available for both Node.js and Python.
Before going ahead with the project, I'd like to ask you to star Crawlee for Python on GitHub, it helps us to spread the word to fellow scraper developers.
2. Connecting to Google Maps
Let's see the steps to connect to Google Maps.
Step 1: Setting up the crawler
The first step is to configure the crawler. We're using PlaywrightCrawler from Crawlee, which gives us powerful tools for automated browsing. We set headless=False to make the browser visible during scraping and allow 5 minutes for the pages to load.
from crawlee.playwright_crawler import PlaywrightCrawler
from datetime import timedelta
# Initialize crawler with browser visibility and timeout settings
crawler = PlaywrightCrawler(
headless=False, # Shows the browser window while scraping
request_handler_timeout=timedelta(
minutes=5
), # Allows plenty of time for page loading
)
Step 2: Handling each page
This function defines how each page is handled when the crawler visits it. It uses context.page to navigate to the target URL.
async def scrape_google_maps(context):
"""
Establishes connection to Google Maps and handles the initial page load
"""
page = context.page
await page.goto(context.request.url)
context.log.info(f"Processing: {context.request.url}")
Step 3: Launching the crawler
Finally, the main function brings everything together. It creates a search URL, sets up the crawler, and starts the scraping process.
import asyncio
async def main():
# Prepare the search URL
search_query = "hotels in bengaluru"
start_url = f"https://www.google.com/maps/search/{search_query.replace(' ', '+')}"
# Tell the crawler how to handle each page it visits
crawler.router.default_handler(scrape_google_maps)
# Start the scraping process
await crawler.run([start_url])
if __name__ == "__main__":
asyncio.run(main())
Let’s combine the above code snippets and save them in a file named gmap_scraper.py:
from crawlee.playwright_crawler import PlaywrightCrawler
from datetime import timedelta
import asyncio
async def scrape_google_maps(context):
"""
Establishes connection to Google Maps and handles the initial page load
"""
page = context.page
await page.goto(context.request.url)
context.log.info(f"Processing: {context.request.url}")
async def main():
"""
Configures and launches the crawler with custom settings
"""
# Initialize crawler with browser visibility and timeout settings
crawler = PlaywrightCrawler(
headless=False, # Shows the browser window while scraping
request_handler_timeout=timedelta(
minutes=5
), # Allows plenty of time for page loading
)
# Tell the crawler how to handle each page it visits
crawler.router.default_handler(scrape_google_maps)
# Prepare the search URL
search_query = "hotels in bengaluru"
start_url = f"https://www.google.com/maps/search/{search_query.replace(' ', '+')}"
# Start the scraping process
await crawler.run([start_url])
if __name__ == "__main__":
asyncio.run(main())
Run the code using:
$ python3 gmap_scraper.py
When everything works correctly, you'll see the output like this:
3. Import dependencies and defining Scraper Class
Let's start with the basic structure and necessary imports:
import asyncio
from datetime import timedelta
from typing import Dict, Optional, Set
from crawlee.playwright_crawler import PlaywrightCrawler
from playwright.async_api import Page, ElementHandle
The GoogleMapsScraper class serves as the main scraper engine:
class GoogleMapsScraper:
def __init__(self, headless: bool = True, timeout_minutes: int = 5):
self.crawler = PlaywrightCrawler(
headless=headless,
request_handler_timeout=timedelta(minutes=timeout_minutes),
)
self.processed_names: Set[str] = set()
async def setup_crawler(self) -> None:
self.crawler.router.default_handler(self._scrape_listings)
This initialization code sets up two crucial components:
- A
PlaywrightCrawlerinstance configured to run either headlessly (without a visible browser window) or with a visible browser - A set to track processed business names, preventing duplicate entries
The setup_crawler method configures the crawler to use our main scraping function as the default handler for all requests.
4. Understanding Google Maps internal code structure
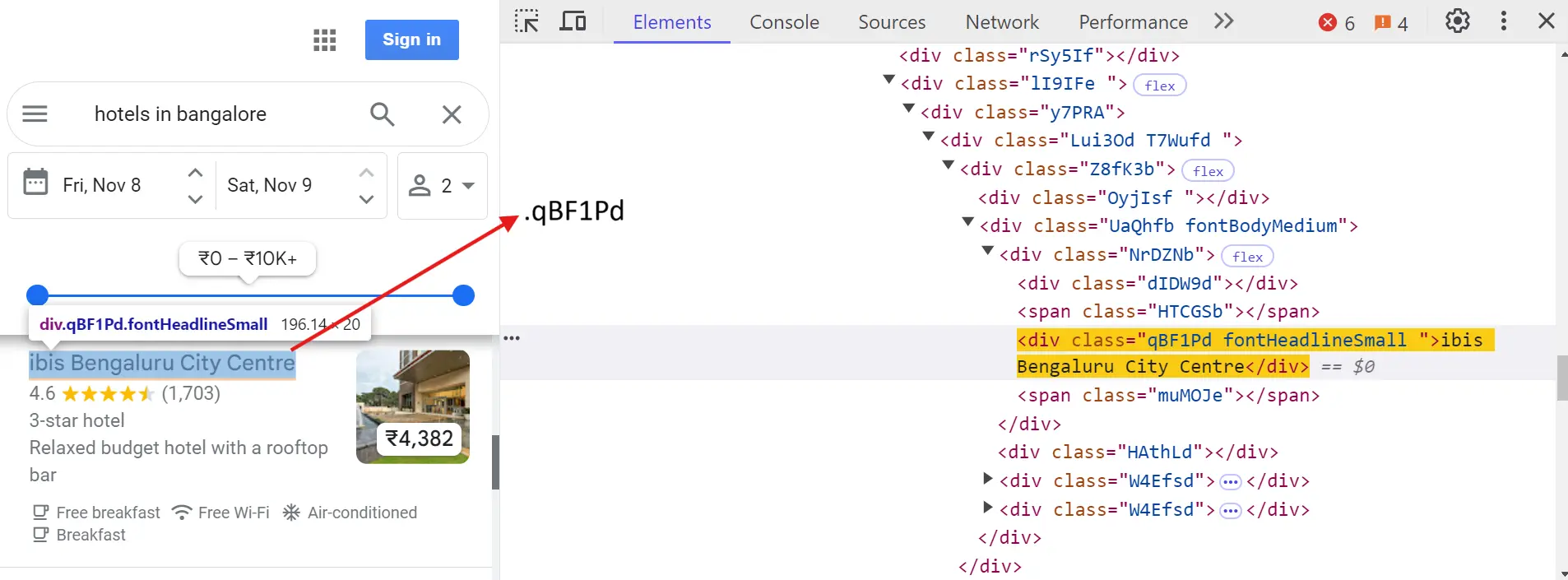
Before we dive into scraping, let's understand exactly what elements we need to target. When you search for hotels in Bengaluru, Google Maps organizes hotel information in a specific structure. Here's a detailed breakdown of how to locate each piece of information.
Hotel name:
Hotel rating:
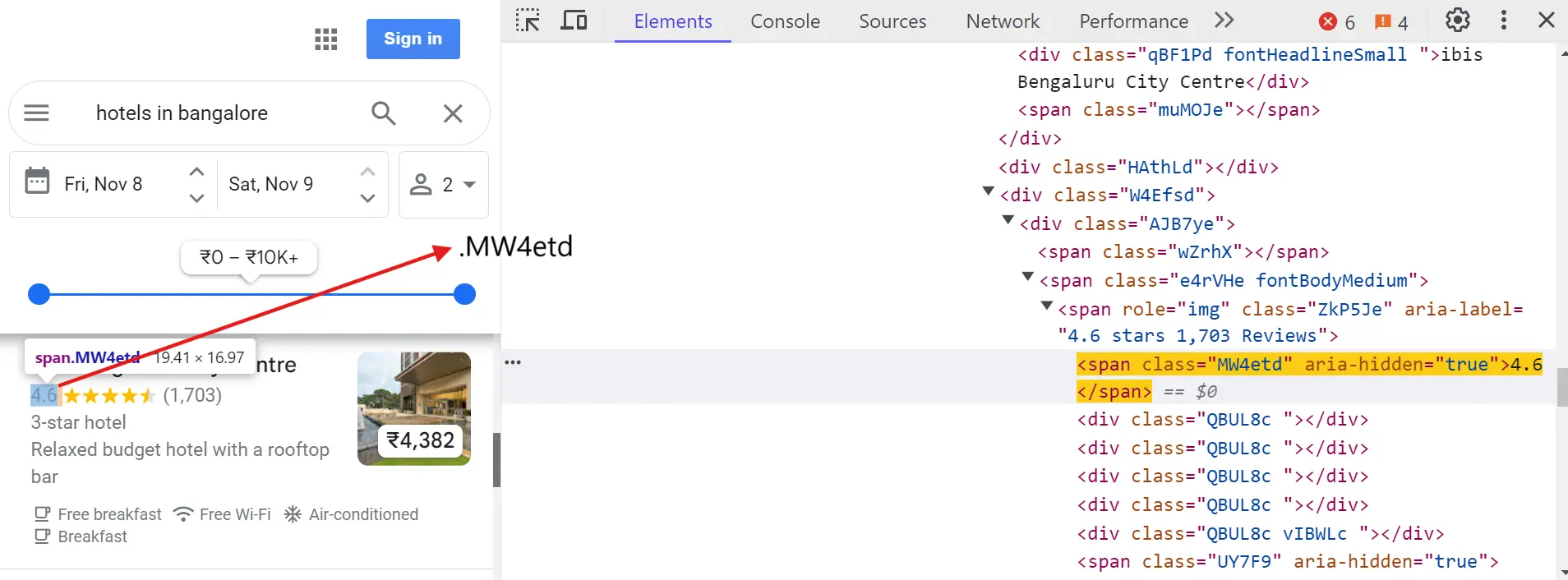
Hotel review count:
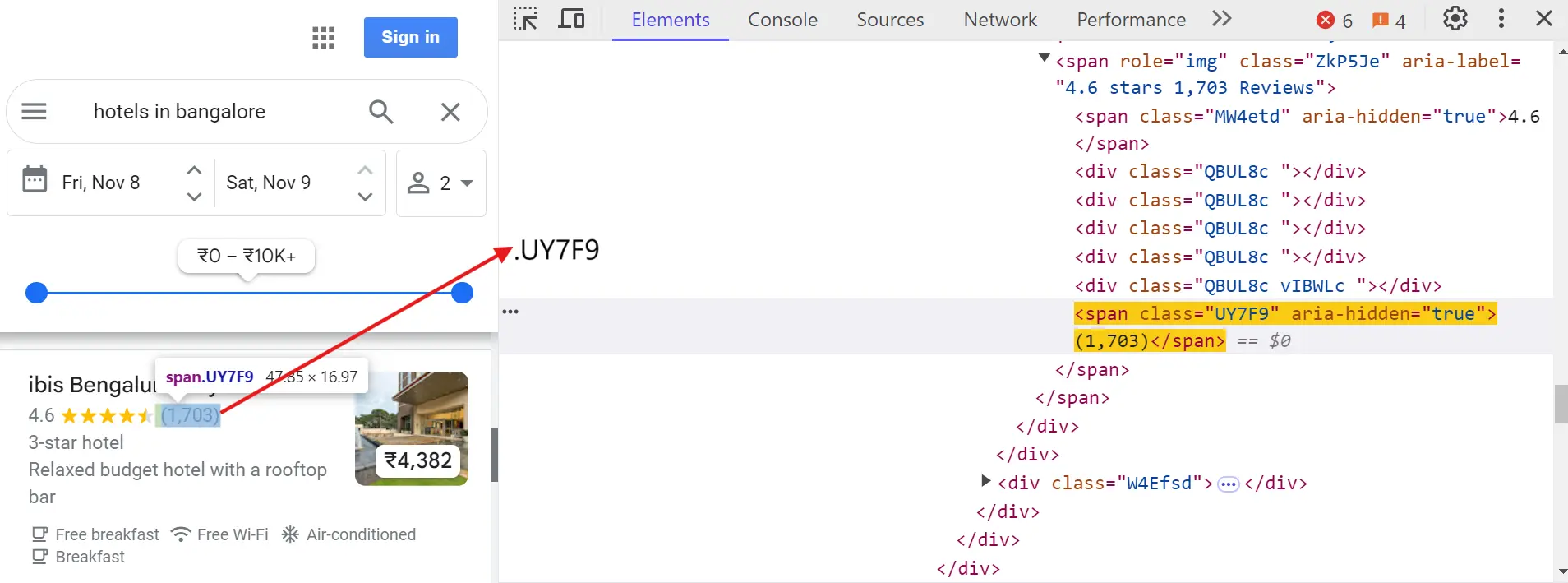
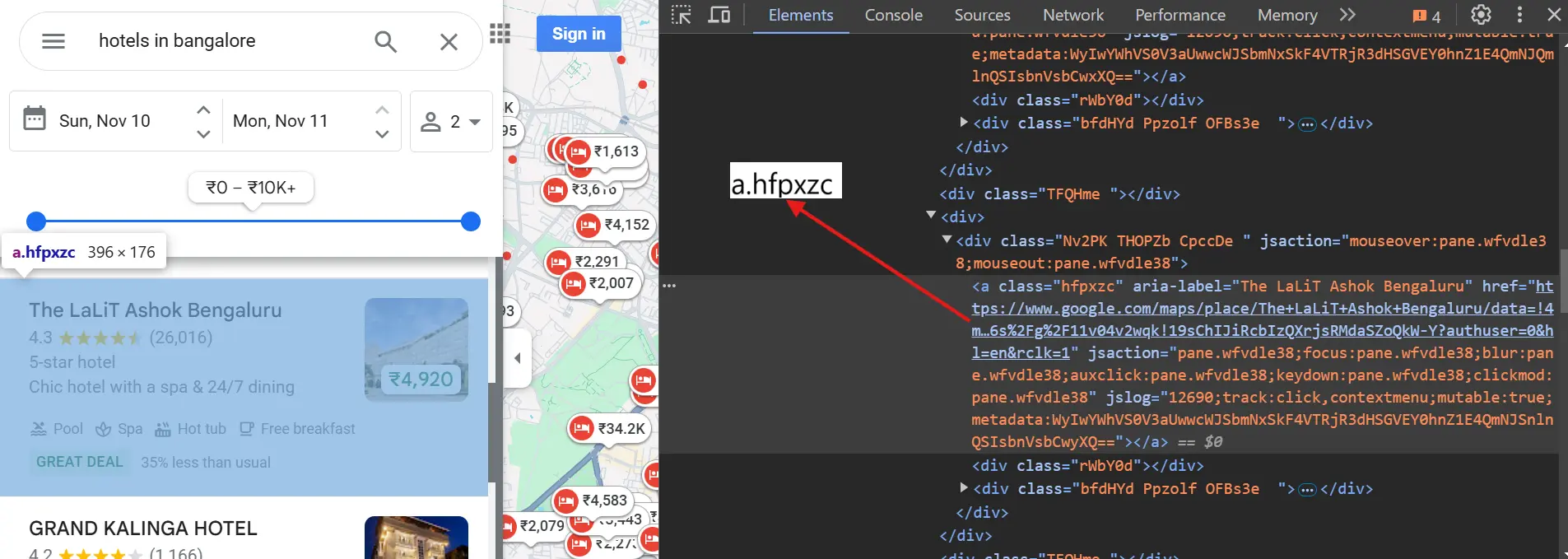
Hotel URL:
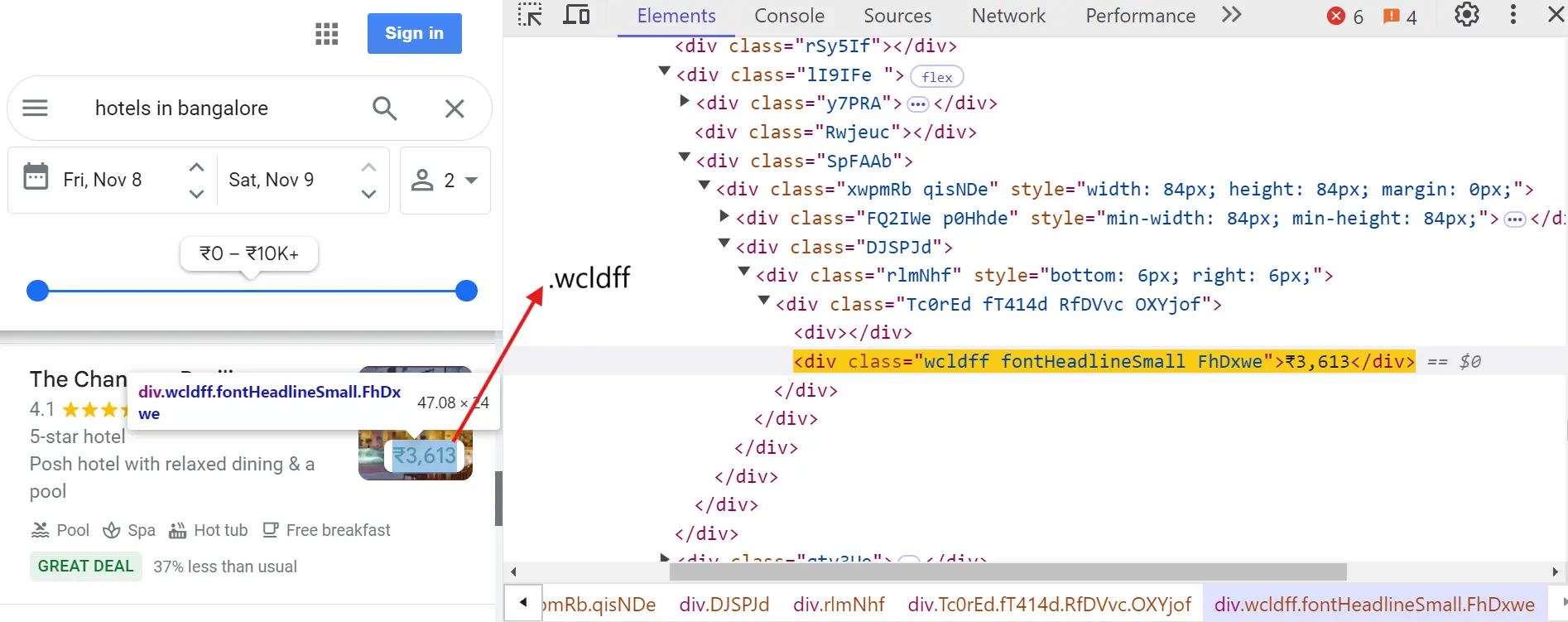
Hotel Price:
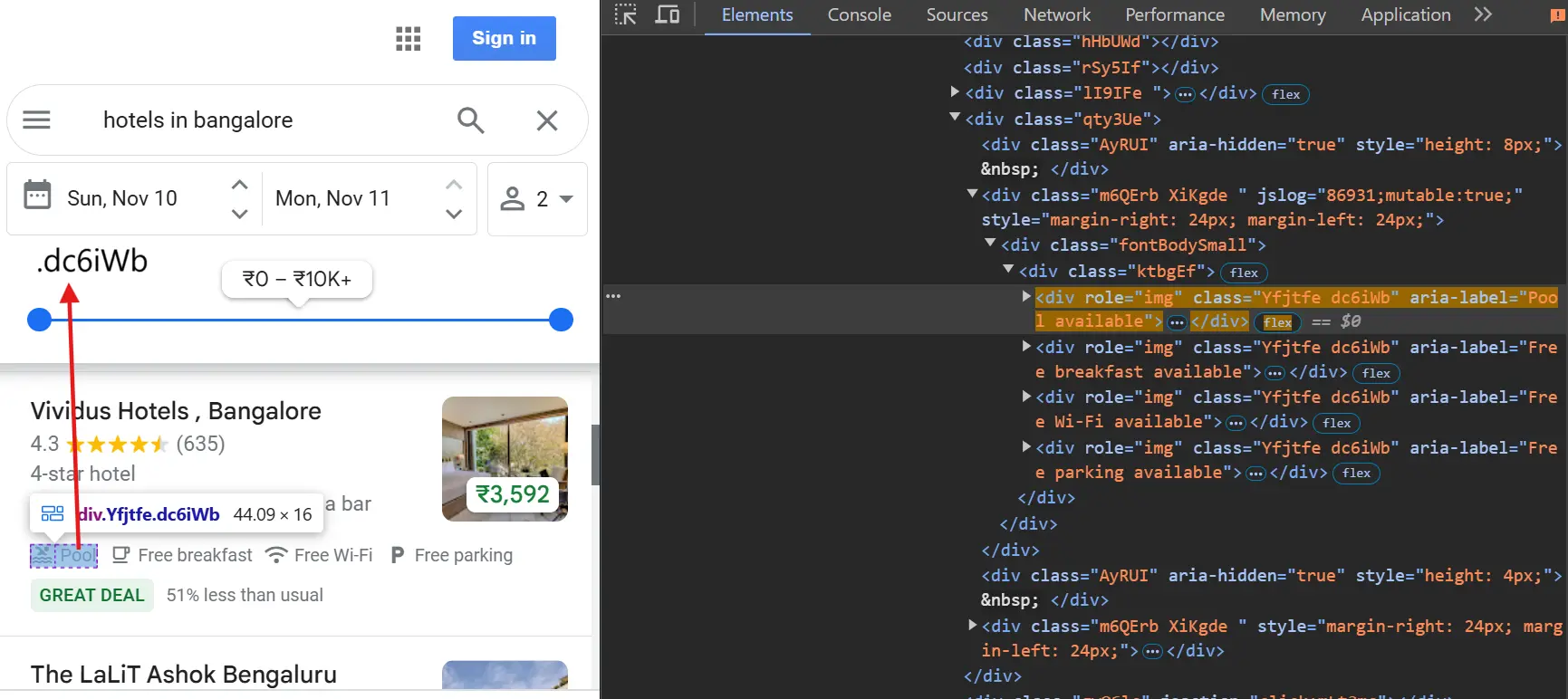
Hotel amenities:
This returns multiple elements as each hotel has several amenities. We'll need to iterate through these.
Quick tips:
- Always verify these selectors before scraping, as Google might update them.
- Use Chrome DevTools (F12) to inspect elements and confirm selectors.
- Some elements might not be present for all hotels (like prices during the off-season).
5. Scraping Google Maps data using identified selectors
Let's build a scraper to extract detailed hotel information from Google Maps. First, create the core scraping function to handle data extraction.
gmap_scraper.py:
async def _extract_listing_data(self, listing: ElementHandle) -> Optional[Dict]:
"""Extract structured data from a single listing element."""
try:
name_el = await listing.query_selector(".qBF1Pd")
if not name_el:
return None
name = await name_el.inner_text()
if name in self.processed_names:
return None
elements = {
"rating": await listing.query_selector(".MW4etd"),
"reviews": await listing.query_selector(".UY7F9"),
"price": await listing.query_selector(".wcldff"),
"link": await listing.query_selector("a.hfpxzc"),
"address": await listing.query_selector(".W4Efsd:nth-child(2)"),
"category": await listing.query_selector(".W4Efsd:nth-child(1)"),
}
amenities = []
amenities_els = await listing.query_selector_all(".dc6iWb")
for amenity in amenities_els:
amenity_text = await amenity.get_attribute("aria-label")
if amenity_text:
amenities.append(amenity_text)
place_data = {
"name": name,
"rating": await elements["rating"].inner_text() if elements["rating"] else None,
"reviews": (await elements["reviews"].inner_text()).strip("()") if elements["reviews"] else None,
"price": await elements["price"].inner_text() if elements["price"] else None,
"address": await elements["address"].inner_text() if elements["address"] else None,
"category": await elements["category"].inner_text() if elements["category"] else None,
"amenities": amenities if amenities else None,
"link": await elements["link"].get_attribute("href") if elements["link"] else None,
}
self.processed_names.add(name)
return place_data
except Exception as e:
context.log.exception("Error extracting listing data")
return None
In the code:
query_selector: Returns first DOM element matching CSS selector, useful for single items like a name or ratingquery_selector_all: Returns all matching elements, ideal for multiple items like amenitiesinner_text(): Extracts text content- Some hotels might not have all the information available - we handle this with 'N/A’
When you run this script, you'll see output similar to this:
{
"name": "GRAND KALINGA HOTEL",
"rating": "4.2",
"reviews": "1,171",
"price": "\u20b91,760",
"link": "https://www.google.com/maps/place/GRAND+KALINGA+HOTEL/data=!4m10!3m9!1s0x3bae160e0ce07789:0xb15bf736f4238e6a!5m2!4m1!1i2!8m2!3d12.9762259!4d77.5786043!16s%2Fg%2F11sp32pz28!19sChIJiXfgDA4WrjsRao4j9Db3W7E?authuser=0&hl=en&rclk=1",
"amenities": [
"Pool available",
"Free breakfast available",
"Free Wi-Fi available",
"Free parking available"
]
}
6. Managing Infinite Scrolling
Google Maps uses infinite scrolling to load more results as users scroll down. We handle this with a dedicated method:
First, we need a function that can handle the scrolling and detect when we've hit the bottom. Copy-paste this new function in the gmap_scraper.py file:
async def _load_more_items(self, page: Page) -> bool:
"""Scroll down to load more items."""
try:
feed = await page.query_selector('div[role="feed"]')
if not feed:
return False
prev_scroll = await feed.evaluate("(element) => element.scrollTop")
await feed.evaluate("(element) => element.scrollTop += 800")
await page.wait_for_timeout(2000)
new_scroll = await feed.evaluate("(element) => element.scrollTop")
if new_scroll <= prev_scroll:
return False
await page.wait_for_timeout(1000)
return True
except Exception as e:
context.log.exception("Error during scroll")
return False
Run this code using:
$ python3 gmap_scraper.py
You should see an output like this:

7. Scrape Listings
The main scraping function ties everything together. It scrapes listings from the page by repeatedly extracting data and scrolling.
async def _scrape_listings(self, context) -> None:
"""Main scraping function to process all listings"""
try:
page = context.page
print(f"\nProcessing URL: {context.request.url}\n")
await page.wait_for_selector(".Nv2PK", timeout=30000)
await page.wait_for_timeout(2000)
while True:
listings = await page.query_selector_all(".Nv2PK")
new_items = 0
for listing in listings:
place_data = await self._extract_listing_data(listing)
if place_data:
await context.push_data(place_data)
new_items += 1
print(f"Processed: {place_data['name']}")
if new_items == 0 and not await self._load_more_items(page):
break
if new_items > 0:
await self._load_more_items(page)
print(f"\nFinished processing! Total items: {len(self.processed_names)}")
except Exception as e:
print(f"Error in scraping: {str(e)}")
The scraper uses Crawlee's built-in storage system to manage scraped data. When you run the scraper, it creates a storage directory in your project with several key components:
datasets/: Contains the scraped results in JSON formatkey_value_stores/: Stores crawler state and metadatarequest_queues/: Manages URLs to be processed
The push_data() method we use in our scraper sends the data to Crawlee's dataset storage as you can see below:
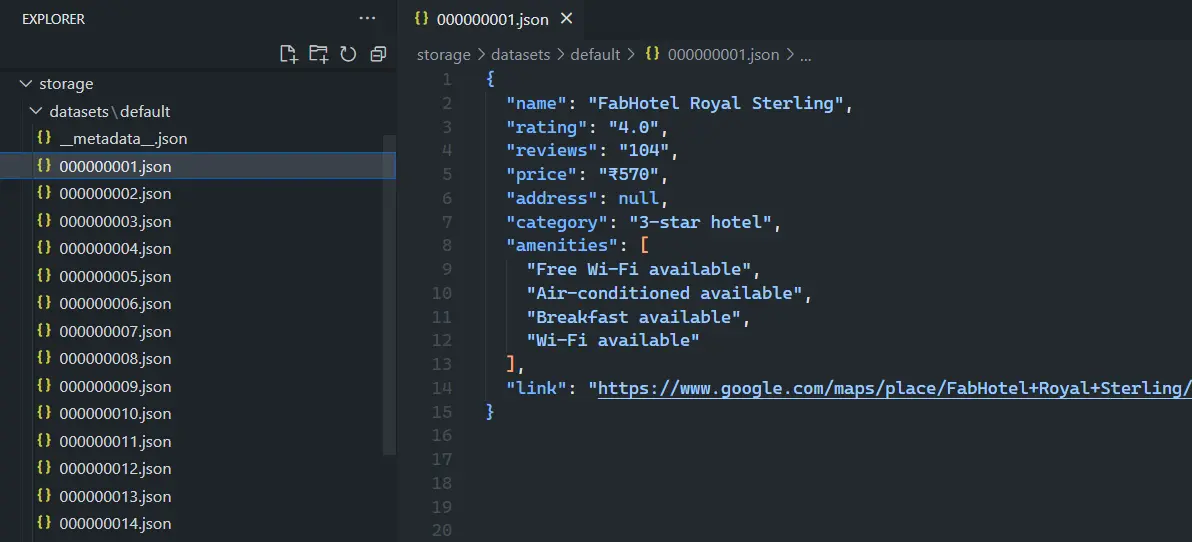
8. Running the Scraper
Finally, we need functions to execute our scraper:
async def run(self, search_query: str) -> None:
"""Execute the scraper with a search query"""
try:
await self.setup_crawler()
start_url = f"https://www.google.com/maps/search/{search_query.replace(' ', '+')}"
await self.crawler.run([start_url])
await self.crawler.export_data_json('gmap_data.json')
except Exception as e:
print(f"Error running scraper: {str(e)}")
async def main():
"""Entry point of the script"""
scraper = GoogleMapsScraper(headless=True)
search_query = "hotels in bengaluru"
await scraper.run(search_query)
if __name__ == "__main__":
asyncio.run(main())
This data is automatically stored and can later be exported to a JSON file using:
await self.crawler.export_data_json('gmap_data.json')
Here's what your exported JSON file will look like:
[
{
"name": "Vividus Hotels, Bangalore",
"rating": "4.3",
"reviews": "633",
"price": "₹3,667",
"amenities": [
"Pool available",
"Free breakfast available",
"Free Wi-Fi available",
"Free parking available"
],
"link": "https://www.google.com/maps/place/Vividus+Hotels+,+Bangalore/..."
}
]
9. Using proxies for Google Maps scraping
When scraping Google Maps at scale, using proxies is very helpful. Here are a few key reasons why:
- Avoid IP blocks: Google Maps can detect and block IP addresses that make an excessive number of requests in a short time. Using proxies helps you stay under the radar.
- Bypass rate limits: Google implements strict limits on the number of requests per IP address. By rotating through multiple IPs, you can maintain a consistent scraping pace without hitting these limits.
- Access location-specific data: Different regions may display different data on Google Maps. Proxies allow you to view listings as if you are browsing from any specific location.
Here's a simple implementation using Crawlee's built-in proxy management. Update your previous code with this to use proxy settings.
from crawlee.playwright_crawler import PlaywrightCrawler
from crawlee.proxy_configuration import ProxyConfiguration
# Configure your proxy settings
proxy_configuration = ProxyConfiguration(
proxy_urls=[
"http://username:password@proxy.provider.com:12345",
# Add more proxy URLs as needed
]
)
# Initialize crawler with proxy support
crawler = PlaywrightCrawler(
headless=True,
request_handler_timeout=timedelta(minutes=5),
proxy_configuration=proxy_configuration,
)
Here, I use a proxy to scrape hotel data in New York City.
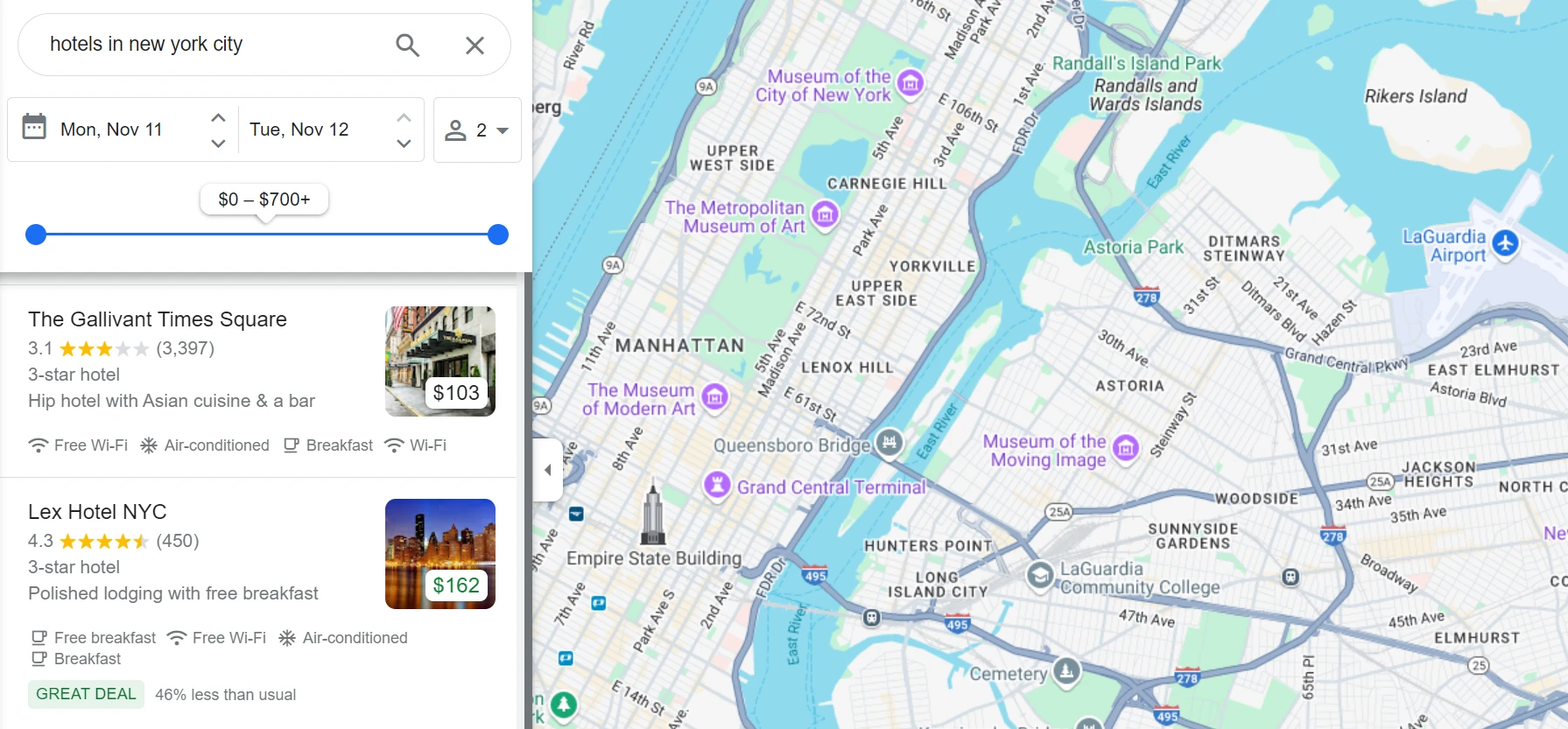
Here's an example of data scraped from New York City hotels using proxies:
{
"name": "The Manhattan at Times Square Hotel",
"rating": "3.1",
"reviews": "8,591",
"price": "$120",
"amenities": [
"Free parking available",
"Free Wi-Fi available",
"Air-conditioned available",
"Breakfast available"
],
"link": "https://www.google.com/maps/place/..."
}
10. Project: Interactive hotel analysis dashboard
After scraping hotel data from Google Maps, you can build an interactive dashboard that helps analyze hotel trends. Here’s a preview of how the dashboard works:
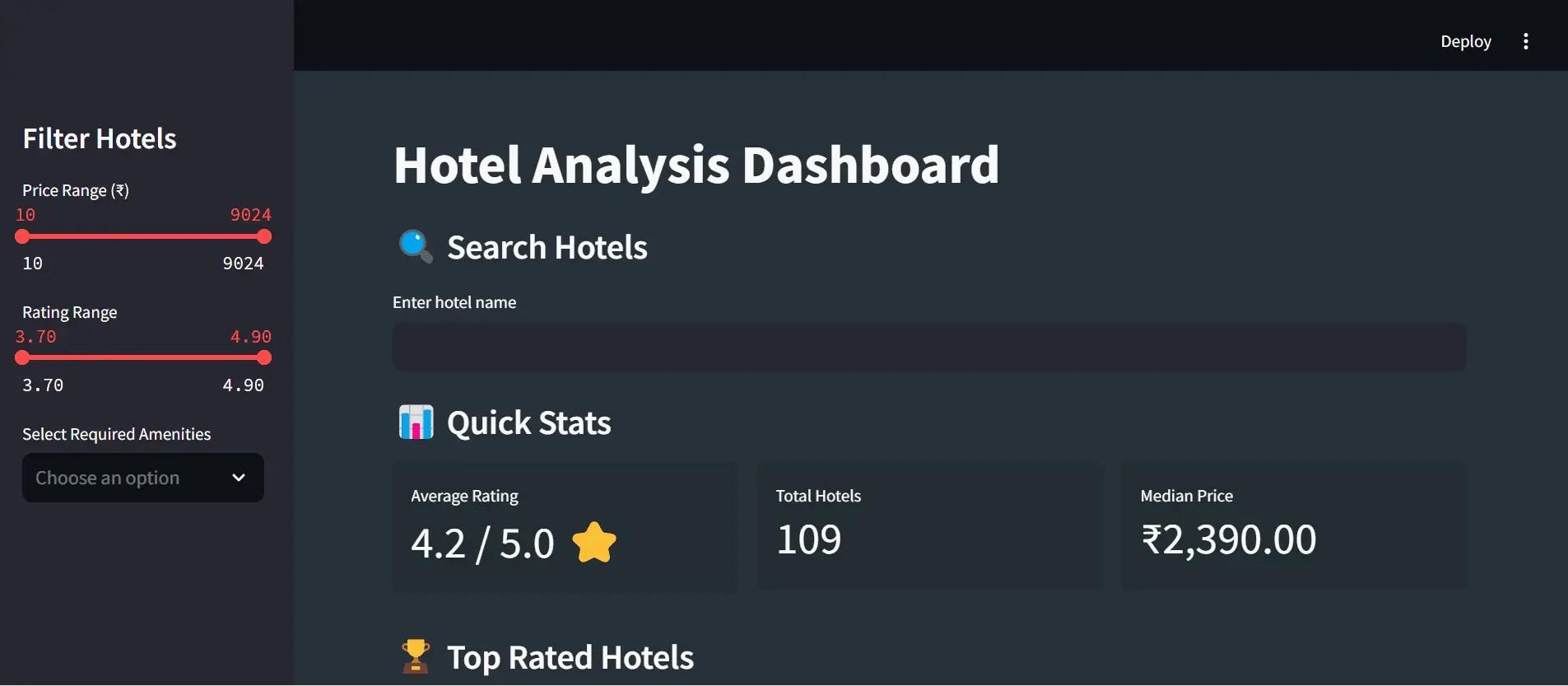
Find the complete info for this dashboard on GitHub: Hotel Analysis Dashboard.
11. Now you’re ready to put everything into action!
Take a look at the complete scripts in my GitHub Gist:
To make it all work:
- Run the basic scraper or proxy-integrated scraper: This will collect the hotel data and store it in a JSON file.
- Run the dashboard script: Load your JSON data and view it interactively in the dashboard.
Wrapping up and next steps
You've successfully built a comprehensive Google Maps scraper that collects and processes hotel data, presenting it through an interactive dashboard. Now you’ve learned about:
- Using Crawlee with Playwright to navigate and extract data from Google Maps
- Using proxies to scale up scraping without getting blocked
- Storing the extracted data in JSON format
- Creating an interactive dashboard to analyze hotel data
We’ve handpicked some great resources to help you further explore web scraping: